


Python – BeautifulSoup的find()和findAll()
1 参数以及比较 BeautifulSoup的find()和findAll()这两个函数在某些方面十分的相似,我们可以使用它们过滤HTML页面,并查找需要的标签组和单个的标签。 这两个函数非常的相似: findAll(tag,attributes,recursive,text,limit,k…
- Python
- 2019-11-10

Python:UnicodeEncodeError: ‘gbk’ codec can’t encode character ‘\xbb’ in position 12305,以及中文乱码的解决方案
刚刚学习了Python没几天,看了《Python网络数据采集》这本书,准备今天在网上试验着爬一个数据,网站是UTF-8编码的,可以在网站的文件头可以看出来 所以我就按照书上的代码照着写了几行代码: #__author__ = 'Administrat #coding=utf-8 from urlli…
- Python
- 2019-10-26
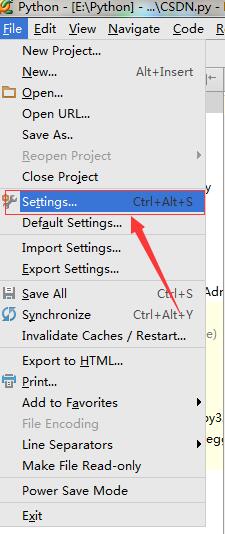
简单粗暴:使用pycharm安装对应的Python版本第三方包
Python的强大除了其简单的语法以及易用性,还有其不得不说的海量的第三库的支持。 但是,我们电脑上由于需要可能安装了多个版本的Python,如Python2.X和Python3.X,这时候我们除了在电脑上要解决多个Python版本共存的问题,还需要针对不同的版本安装支持不同版本的第三方库,而且在安…
- Python
- 2019-10-25
解决Python爬虫在爬资源过程中使用urlretrieve函数下载文件不完全且避免下载时长过长陷入死循环,并在下载文件的过程中显示下载进度
import urllib from urllib.request import urlretrieve #解决urlretrieve下载文件不完全的问题且避免下载时长过长陷入死循环 def auto_down(url,filename): try: urlretrieve(url,filename…
- Python
- 2019-10-24