

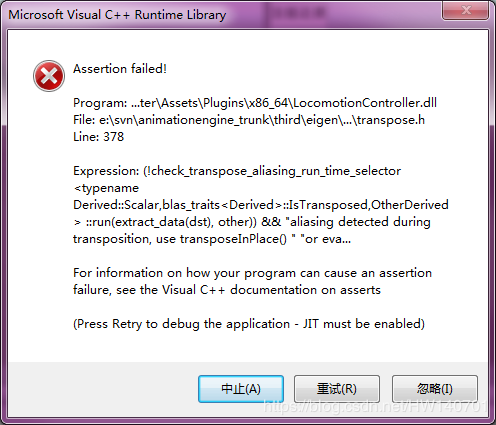


![Python – 安装onnxruntime-gpu出现ERROR: Could not install packages due to an OSError: [Errno 2] No such file or directory: ‘…\\numpy-1.23.1.dist-info\\METADATA’](https://www.stubbornhuang.com/wp-content/uploads/2022/11/wp_editor_md_a6c94ab3d915e2a9232f2fd7b2f45bd3.jpg)

Python – 写爬虫时需要用到那些第三方库
网络爬虫的执行步骤大致可以分为以下几步:
- 进行网络请求,获取网页内容;
- 解析网页信息,获取有用信息;
- 存储有用信息,与数据库交互;
在使用Python写一些简单工具爬虫时,上述三个步骤都有比较多的第三方库可供我们选择。
1 网页请求
- urllib:urllib是python内置的处理HTTP请求的库;
- requests:基于urllib编写,目前Python最简单易用的Http请求库,爬虫首选http请求库;
- selenium:selenium是一个 web 的自动化测试工具,可直接调用浏览器模拟人类操作,一般在反爬虫严格或者需要直接使用浏览器操作的网站下使用;
- aiohttp:基于asyncio实现的HTTP框架,异步操作借助于 async/await 关键字,使用异步库进行数据抓取,可以大大提高效率;
2 网页解析
- re:正则匹配,直接使用正则表达式解析网页内容,难度较大;
- html.parser:Python内置的Html解析库;
- BeautifulSoup:Beautiful Soup是一个可以从HTML或XML文件中提取数据的Python库,学习曲线较低,非常容易上手;
- lxml:xml是一个高性能的Python HTML/XML解析器,使用C编写,用于快速定位特定元素以及节点信息;
- pyquery:jQuery 的 Python 实现,能够以 jQuery 的语法来操作解析 HTML 文档,易用性和解析速度都很好;
3 信息存储,数据库操作
- pymysql:一个纯 Python 实现的 MySQL 客户端操作库;
- pymongo:一个用于直接连接 mongodb 数据库进行查询操作的库;
- redisdump:一个用于 redis 数据导入/导出的工具;
参考链接
本文作者:StubbornHuang
版权声明:本文为站长原创文章,如果转载请注明原文链接!
原文标题:Python – 写爬虫时需要用到那些第三方库
原文链接:https://www.stubbornhuang.com/2345/
发布于:2022年09月07日 15:52:56
修改于:2023年06月21日 18:06:55
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。
文章末尾
评论
56