深度学习 – 语音识别框架wenet中的CTC Prefix Beam Search算法的实现
1 Wenet中的CTC Prefix Beam Search Decode的实现
下面是Wenet网络的流程图
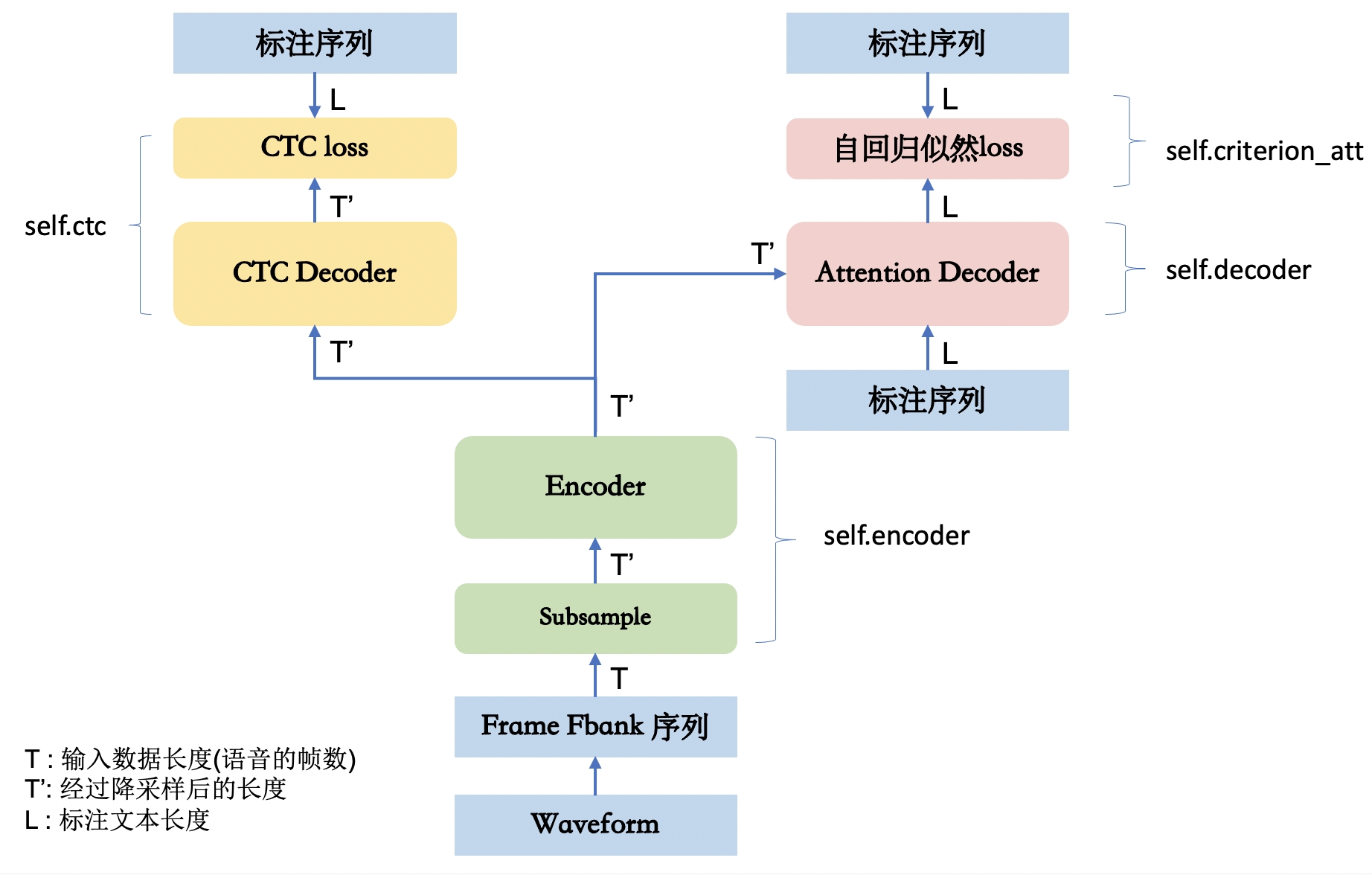
上图来自于:http://placebokkk.github.io/wenet/2021/06/04/asr-wenet-nn-1.html
语音特征数据在经过Encoder后会使用CTC进行对齐,而我们在使用Wenet进行推理的时候就必须对CTC的输出进行解码,常用的解码方法有Greedy Search、Beam Search、Prefix Beam Search,在Wenet中采用了目前常用并且解码效果较好的Prefix Beam Search算法,其核心代码位于asr_model.py的_ctc_prefix_beam_search方法中,原始代码如下
def _ctc_prefix_beam_search(
self,
speech: torch.Tensor,
speech_lengths: torch.Tensor,
beam_size: int,
decoding_chunk_size: int = -1,
num_decoding_left_chunks: int = -1,
simulate_streaming: bool = False,
) -> Tuple[List[List[int]], torch.Tensor]:
""" CTC prefix beam search inner implementation
Args:
speech (torch.Tensor): (batch, max_len, feat_dim)
speech_length (torch.Tensor): (batch, )
beam_size (int): beam size for beam search
decoding_chunk_size (int): decoding chunk for dynamic chunk
trained model.
<0: for decoding, use full chunk.
>0: for decoding, use fixed chunk size as set.
0: used for training, it's prohibited here
simulate_streaming (bool): whether do encoder forward in a
streaming fashion
Returns:
List[List[int]]: nbest results
torch.Tensor: encoder output, (1, max_len, encoder_dim),
it will be used for rescoring in attention rescoring mode
"""
assert speech.shape[0] == speech_lengths.shape[0]
assert decoding_chunk_size != 0
batch_size = speech.shape[0]
# For CTC prefix beam search, we only support batch_size=1
assert batch_size == 1
# Let's assume B = batch_size and N = beam_size
# 1. Encoder forward and get CTC score
encoder_out, encoder_mask = self._forward_encoder(
speech, speech_lengths, decoding_chunk_size,
num_decoding_left_chunks,
simulate_streaming) # (B, maxlen, encoder_dim)
maxlen = encoder_out.size(1)
ctc_probs = self.ctc.log_softmax(
encoder_out) # (1, maxlen, vocab_size)
ctc_probs = ctc_probs.squeeze(0)
# cur_hyps: (prefix, (blank_ending_score, none_blank_ending_score))
cur_hyps = [(tuple(), (0.0, -float('inf')))]
# 2. CTC beam search step by step
for t in range(0, maxlen):
logp = ctc_probs[t] # (vocab_size,)
# key: prefix, value (pb, pnb), default value(-inf, -inf)
next_hyps = defaultdict(lambda: (-float('inf'), -float('inf')))
# 2.1 First beam prune: select topk best
top_k_logp, top_k_index = logp.topk(beam_size) # (beam_size,)
for s in top_k_index:
s = s.item()
ps = logp[s].item()
for prefix, (pb, pnb) in cur_hyps:
last = prefix[-1] if len(prefix) > 0 else None
if s == 0: # blank
n_pb, n_pnb = next_hyps[prefix]
n_pb = log_add([n_pb, pb + ps, pnb + ps])
next_hyps[prefix] = (n_pb, n_pnb)
elif s == last:
# Update *ss -> *s;
n_pb, n_pnb = next_hyps[prefix]
n_pnb = log_add([n_pnb, pnb + ps])
next_hyps[prefix] = (n_pb, n_pnb)
# Update *s-s -> *ss, - is for blank
n_prefix = prefix + (s, )
n_pb, n_pnb = next_hyps[n_prefix]
n_pnb = log_add([n_pnb, pb + ps])
next_hyps[n_prefix] = (n_pb, n_pnb)
else:
n_prefix = prefix + (s, )
n_pb, n_pnb = next_hyps[n_prefix]
n_pnb = log_add([n_pnb, pb + ps, pnb + ps])
next_hyps[n_prefix] = (n_pb, n_pnb)
# 2.2 Second beam prune
next_hyps = sorted(next_hyps.items(),
key=lambda x: log_add(list(x[1])),
reverse=True)
cur_hyps = next_hyps[:beam_size]
hyps = [(y[0], log_add([y[1][0], y[1][1]])) for y in cur_hyps]
return hyps, encoder_out
从上述_ctc_prefix_beam_search的代码我们可以看到,语音特征数据先经过Encoder,然后将Encoder的输出输入到CTC中得到CTC的的输出结果,然后对CTC的输出结果进行Prefix Beam Seach算法,找到给定的Beam size个最佳路径也就是语音识别的Beam size个最佳结果,我们将上述_ctc_prefix_beam_search的Prefix Beam Search算法单独提取出来,如下所示
import math
from typing import List, Tuple
from collections import defaultdict
import torch
def log_add(args: List[int]) -> float:
"""
Stable log add
"""
if all(a == -float('inf') for a in args):
return -float('inf')
a_max = max(args)
lsp = math.log(sum(math.exp(a - a_max) for a in args))
return a_max + lsp
def ctc_prefix_beam_search_decode(ctc_probs,beam_size,blank_id):
maxlen = ctc_probs.size(1)
cur_hyps = [(tuple(), (0.0, -float('inf')))]
for t in range(0, maxlen):
logp = ctc_probs[t] # (vocab_size,)
# key: prefix, value (pb, pnb), default value(-inf, -inf)
next_hyps = defaultdict(lambda: (-float('inf'), -float('inf')))
# 2.1 First beam prune: select topk best
top_k_logp, top_k_index = logp.topk(beam_size) # (beam_size,)
for s in top_k_index:
s = s.item()
ps = logp[s].item()
for prefix, (pb, pnb) in cur_hyps:
last = prefix[-1] if len(prefix) > 0 else None
if s == blank_id: # blank
n_pb, n_pnb = next_hyps[prefix]
n_pb = log_add([n_pb, pb + ps, pnb + ps])
next_hyps[prefix] = (n_pb, n_pnb)
elif s == last:
# Update *ss -> *s;
n_pb, n_pnb = next_hyps[prefix]
n_pnb = log_add([n_pnb, pnb + ps])
next_hyps[prefix] = (n_pb, n_pnb)
# Update *s-s -> *ss, - is for blank
n_prefix = prefix + (s,)
n_pb, n_pnb = next_hyps[n_prefix]
n_pnb = log_add([n_pnb, pb + ps])
next_hyps[n_prefix] = (n_pb, n_pnb)
else:
n_prefix = prefix + (s,)
n_pb, n_pnb = next_hyps[n_prefix]
n_pnb = log_add([n_pnb, pb + ps, pnb + ps])
next_hyps[n_prefix] = (n_pb, n_pnb)
# 2.2 Second beam prune
next_hyps = sorted(next_hyps.items(),
key=lambda x: log_add(list(x[1])),
reverse=True)
cur_hyps = next_hyps[:beam_size]
hyps = [(y[0], log_add([y[1][0], y[1][1]])) for y in cur_hyps]
if __name__ == '__main__':
ctc_probs = torch.Tensor([0.25,0.40,0.35, 0.4,0.35,0.25,0.1,0.5,0.4])
ctc_probs = ctc_probs.reshape(3,3)
ctc_prefix_beam_search_decode(ctc_probs, 3, 0)
不得不说,这个代码实现的思路非常清晰,结合Prefix Beam Search算法的论文以及相关的介绍的博文,然后再参考上述代码,会很快的理解之前看起来比较晦涩的Prefix Beam Search算法,wenet还提供了该算法相应的C++实现,路径在wenet\runtime\core\decoder的ctc_prefix_beam_search.h和ctc_prefix_beam_search.cc下,有兴趣的可以参考以下。
欢迎扫码关注我的微信公众号,及时获取文章更新

本文作者:StubbornHuang
版权声明:本文为站长原创文章,如果转载请注明原文链接!
原文标题:深度学习 – 语音识别框架wenet中的CTC Prefix Beam Search算法的实现
原文链接:https://www.stubbornhuang.com/2478/
发布于:2023年01月13日 10:21:34
修改于:2023年06月21日 17:17:32
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






评论
72