




Transformer – 理解Transformer必看系列之,1 Self-Attention自注意力机制与多头注意力原理
转载自:
链接:https://www.ylkz.life/deeplearning/p10553832/
作者:空字符
修改文章少量行文
1 引言
今天要和大家介绍的一篇论文是谷歌2017年所发表的一篇论文,名字叫做Attention is all you need,当然,网上已经有了大量的关于这篇论文的解析,不过好菜不怕晚笔者只是在这里谈谈自己对于它的理解以及运用。
对于这篇论文,笔者大概会陆续通过7篇文章来进行介绍:
- 1 Transformer中多头注意力机制的思想与原理;
- 2 Transformer的位置编码与编码解码过程;
- 3 Transformer的网络结构与自注意力机制实现;
- 4 Transformer的实现过程;
- 5 基于Transformer的翻译模型;
- 6 基于Transformer的文本分类模型;
- 7 基于Transformer的对联生成模型
希望通过这一系列的7篇文章能够让大家对Transformer有一个比较清楚的认识与理解。下面,就让我们正式走进对于这篇论文的解读中来。
2 动机
2.1 面临问题
按照我们一贯解读论文的顺序,首先让我们先一起来看看作者当时为什么要提出Transformer这个模型?需要解决什么样的问题?现在的模型有什么样的缺陷?
在论文的摘要部分作者提到,现在主流的序列模型都是基于复杂的循环神经网络或者是卷积神经网络构造而来的Encoder-Decoder模型,并且就算是目前性能最好的序列模型也都是基于注意力机制下的Encoder-Decoder架构。为什么作者会不停的提及这些传统的Encoder-Decoder模型呢?接着,作者在介绍部分谈到,由于传统的Encoder-Decoder架构在建模过程中,下一个时刻的计算过程会依赖于上一个时刻的输出,而这种固有的属性就限制了传统的Encoder-Decoder模型就不能以并行的方式进行计算,如下图所示。
This inherently sequential nature precludes parallelization within training examples, which becomes critical at longer sequence lengths, as memory constraints limit batching across examples.
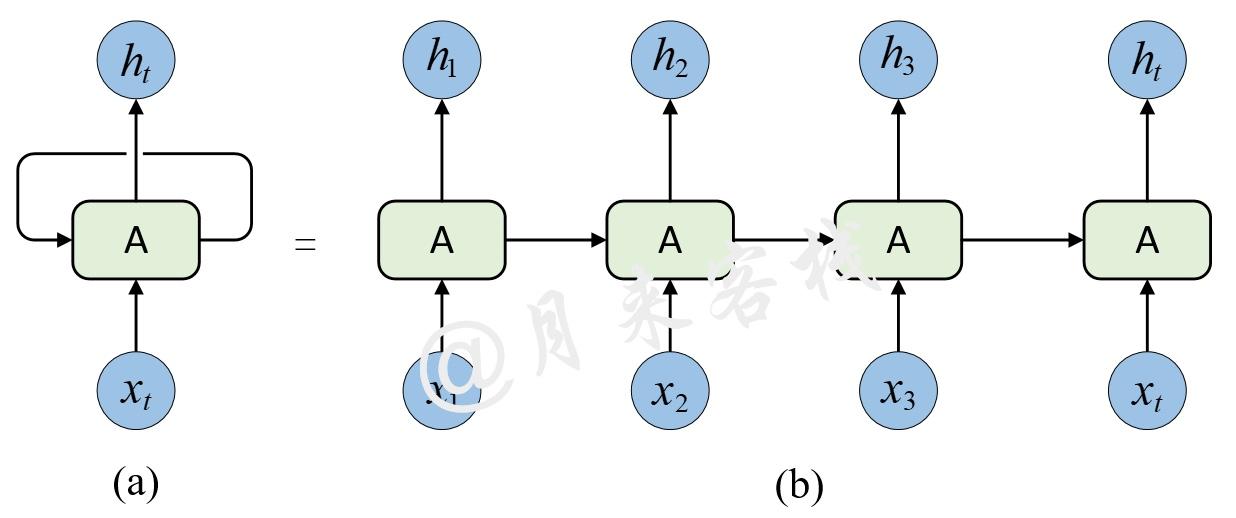
随后作者谈到,尽管最新的研究工作已经能够使得传统的循环神经网络在计算效率上有了很大的提升,但是本质的问题依旧没有得到解决。
Recent work has achieved significant improvements in computational efficiency through factorization tricks and conditional computation, while also improving model performance in case of the latter. The fundamental constraint of sequential computation, however, remains.
2.2 解决思路
因此,在这篇论文中,作者首次提出了一种全新的Transformer架构来解决这一问题。Transformer架构的优点在于它完全摈弃了传统的循环结构,取而代之的是只通过注意力机制来计算模型输入与输出的隐含表示,而这种注意力的名字就是大名鼎鼎的自注意力机制(self-attention)。
To the best of our knowledge, however, the Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence- aligned RNNs or convolution.
总体来说,所谓自注意力机制就是通过某种运算来直接计算得到句子在编码过程中每个位置上的注意力权重;然后再以权重和的形式来计算得到整个句子的隐含向量表示。最终,Transformer架构就是基于这种的自注意力机制而构建的Encoder-Decoder模型。
3 技术手段
在介绍完整篇论文的提出背景后,下面就让我们一起首先来看一看自注意力机制的庐山真面目,然后再来探究整体的网络架构。
3.1 self-Attention
首先需要明白一点的是,所谓的自注意力机制其实就是论文中所指代的”Scaled Dot-Product Attention“。在论文中作者说道,注意力机制可以描述为将query和一系列的key-value对映射到某个输出的过程,而这个输出的向量就是根据query和key计算得到的权重作用于value上的权重和。
An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key.
不过想要更加深入的理解query、key和value的含义,得需要结合Transformer的解码过程,这部分内容将会在后续进行介绍。 具体的,自注意力机制的结构如下图所示。
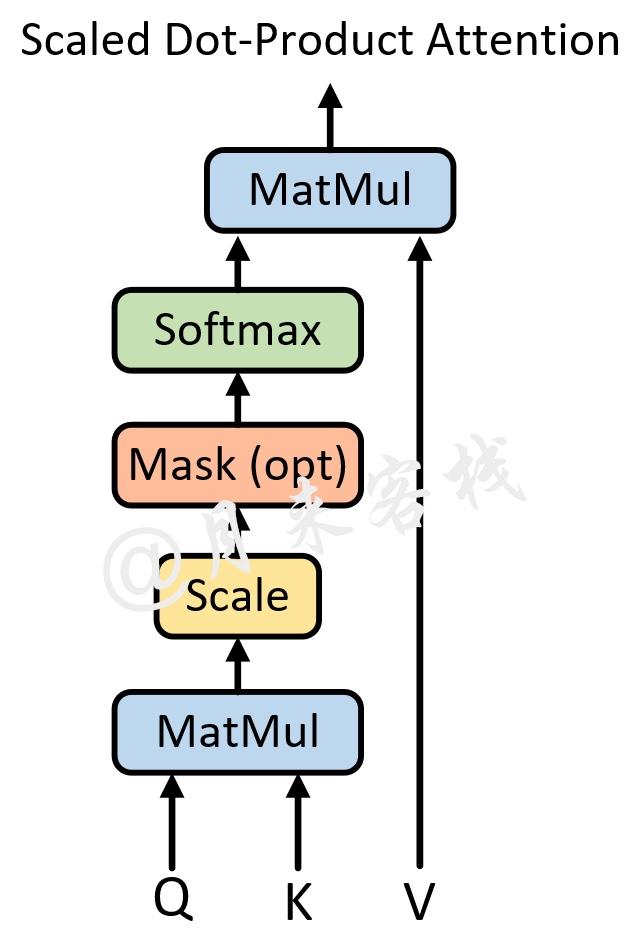
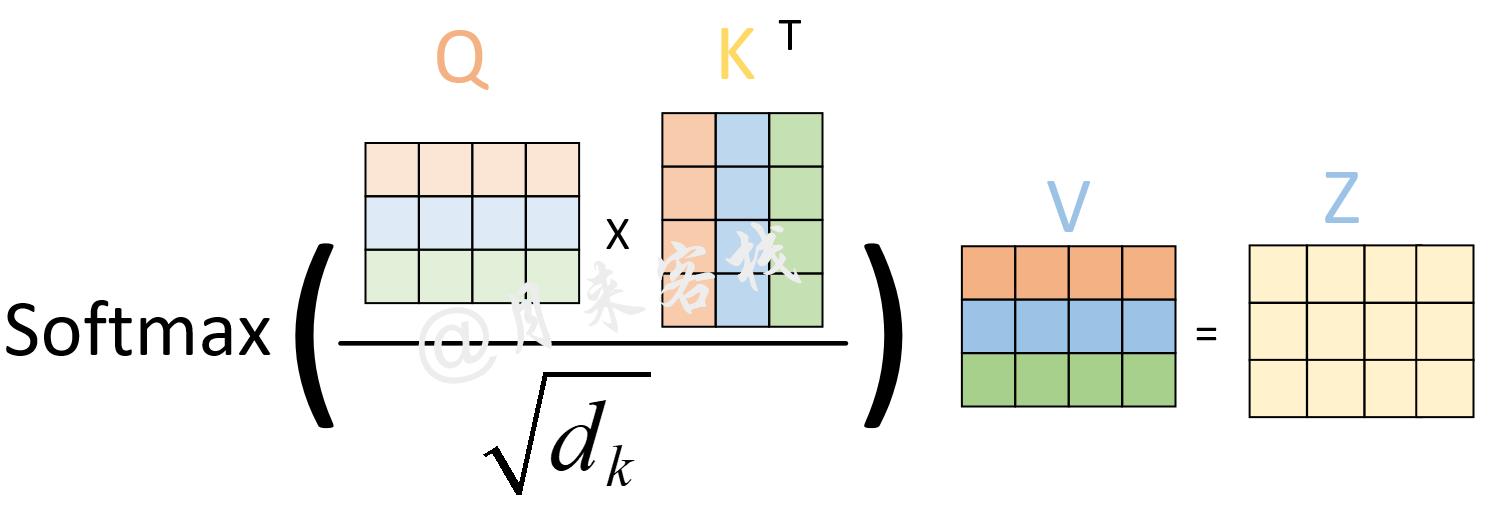
从上图可以看出,自注意力机制的核心过程就是通过Q和K计算得到注意力权重;然后再作用于V得到整个权重和输出。具体的,对于输入Q、K和V来说,其输出向量的计算公式为:
其中Q、K和V分别为3个矩阵,且其维度分别为d_{q},d_{k},d_{v}(从后面的计算过程其实可以发现d_{q}=d_{v})。上述公式中除以\sqrt{d_{k}}就是上图中所指的scale。
之所以要进行缩放这一步是因为通过实验作者发现,对于较大的d_{k}来说在完成QK^{T}后将会得到很大的值,而这将导致在经过softmax操作后产生非常小的梯度,不利于网络的训练。
We suspect that for large values of dk, the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients.
如果仅仅只是看着上图的结构以及公式中的计算过程显然是不那么容易理解自注意力机制的含义,例如初学者最困惑的一个问题就是上图中的Q、K和V分别是怎么来的?下面,我们来看一个实际的计算示例。现在,假设输入序列为“我 是 谁”,且已经通过某种方式得到了1个形状为3 \times 4的矩阵来进行表示,那么通过下图所示的过程便能计算得到Q、K和V。
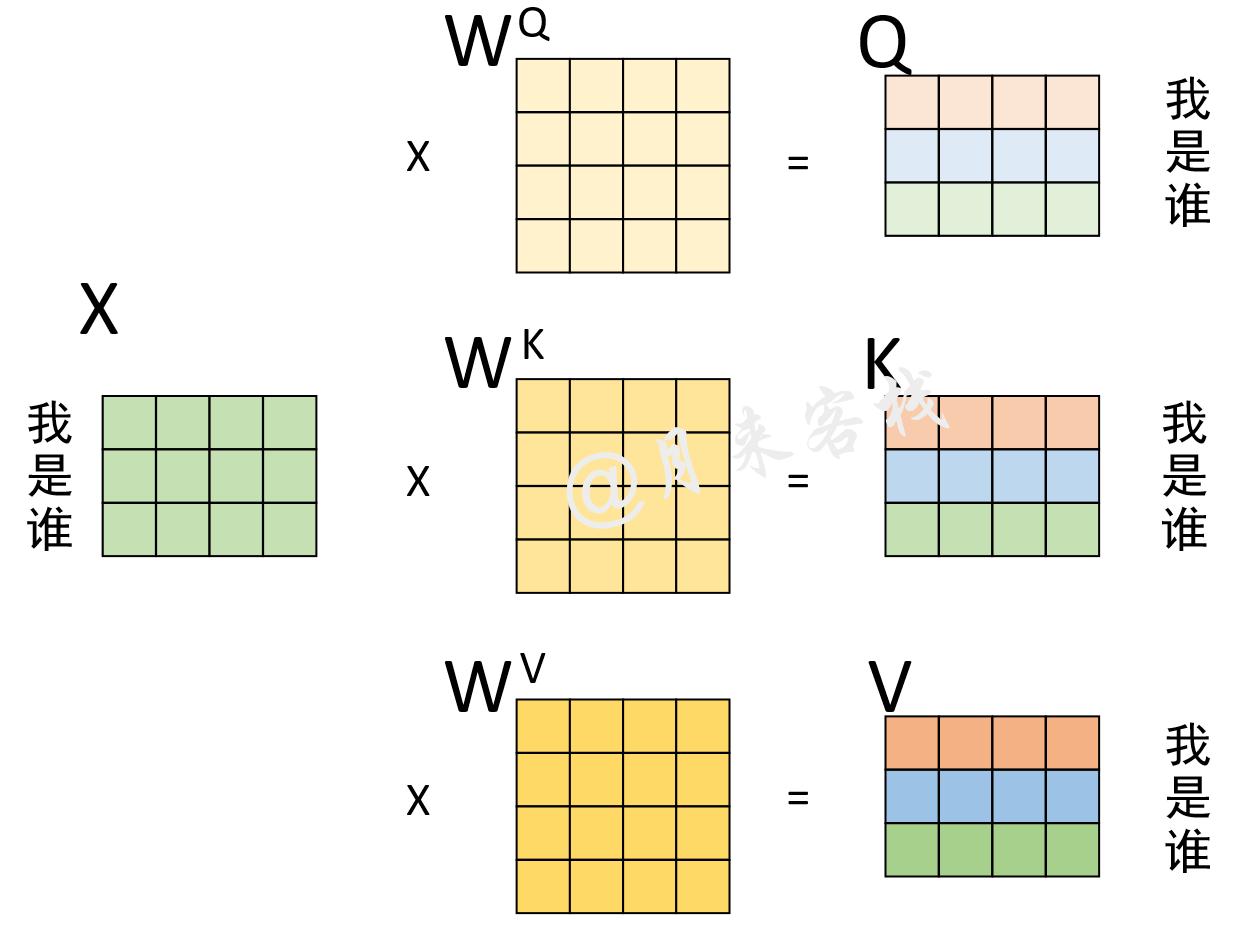
从上图的计算过程可以看出,Q、K和V其实就是输入X分别乘以3个不同的矩阵计算而来(这仅仅局限于Encoder和Decoder在各自输入部分利用自注意力机制进行编码的过程,Encoder和Decoder交互部分的Q、K和V另有指代)。此处对于计算得到的Q、K、V,你可以理解为这是对于同一个输入进行3次不同的线性变换来表示其不同的3种状态。在计算得到Q、K、V之后,就可以进一步计算得到权重向量,计算过程如下图所示。
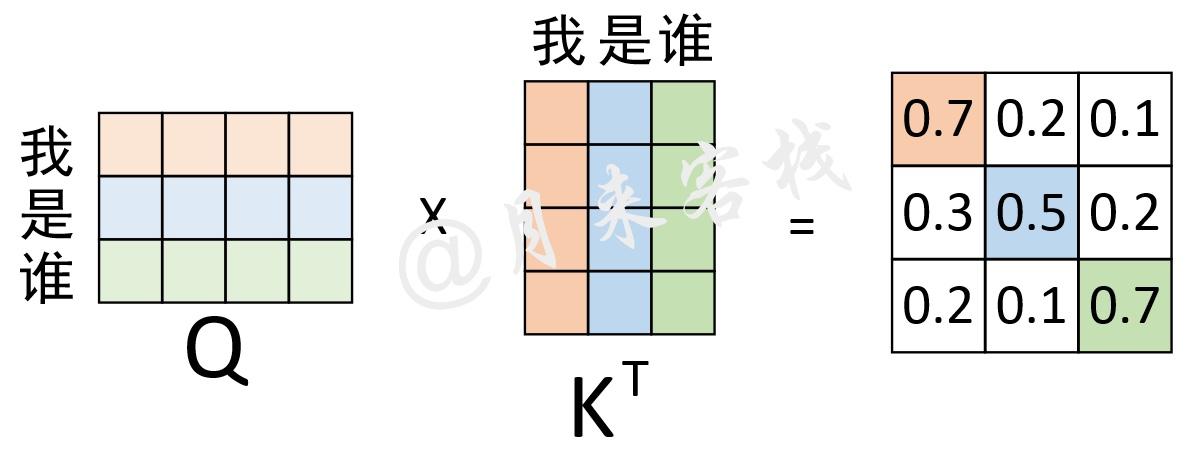
如上图所示,在经过上述过程计算得到了这个注意力权重矩阵之后我们不禁就会问到,这些权重值到底表示的是什么呢?
对于权重矩阵的第1行来说,0.7表示的就是“我”与“我”的注意力值;0.2表示的就是“我”与“是”的注意力值;0.1表示的就是“我”与”谁”的注意力值。换句话说,在对序列中的”我“进行编码时,应该将0.7的注意力放在“我”上,0.2的注意力放在“是”上,将0.1的注意力放在“谁”上。
同理,对于权重矩阵的第3行来说,其表示的含义就是,在对序列中“谁”进行编码时,应该将0.2的注意力放在“我”上,将0.1的注意力放在“是”上,将0.7的注意力放在“谁”上。从这一过程可以看出,通过这个权重矩阵模型就能轻松的知道在编码对应位置上的向量时,应该以何种方式将注意力集中到不同的位置上。
不过从上面的计算结果还可以看到一点就是,模型在对当前位置的信息进行编码时,会过度的将注意力集中于自身的位置(虽然这符合常识)而可能忽略了其它位置。因此,作者采取的一种解决方案就是采用多头注意力机制(MultiHeadAttention),这部分内容我们将在稍后看到。
It expands the model’s ability to focus on different positions. Yes, in the example above, z1 contains a little bit of every other encoding, but it could be dominated by the the actual word itself.
在通过上图的过程计算得到权重矩阵后,便可以将其作用于V,进而得到最终的编码输出,计算过程如下图所示。
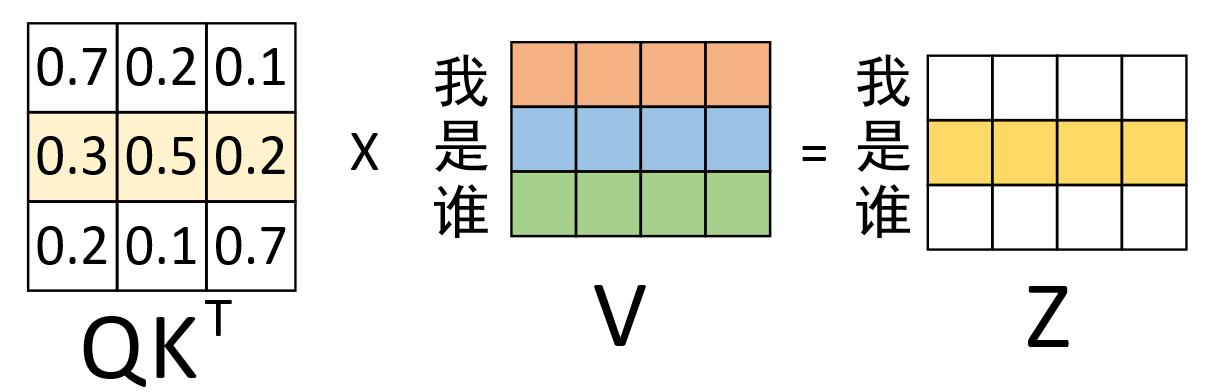
根据上图所示的过程,我们便能够得到最后编码后的输出向量。当然,对于上述过程我们还可以换个角度来进行观察,如下图所示。

从上图可以看出,对于最终输出“是”的编码向量来说,它其实就是原始“我 是 谁”3个向量的加权和,而这也就体现了在对“是”进行编码时注意力权重分配的全过程。
当然,对于整个计算的过程,我们还可以通过下图所示的过程来进行表示。
可以看出通过这种自注意力机制确实解决了作者在论文伊始所提出的传统序列模型在编码过程中都需顺序进行的弊端的问题,有了自注意力机制后,仅仅只需要对原始输入进行几次矩阵变换便能够得到最终包含有不同位置注意力信息的编码向量。
对于自注意力机制的核心部分到这里就介绍完了,不过里面依旧有很多细节之处没有进行介绍。例如Encoder和Decoder在进行交互时的Q、K、V是如何得到的?自注意机制结构图中所标记的Mask(opt)操作是什么意思,什么情况下会用到等等?这些内容将会在后续逐一进行介绍。下面,让我们继续进入到MultiHeadAttention机制的探索中。
3.2 MultiHeadAttention
经过上面内容的介绍,我们算是在一定程度上对于自注意力机制有了清晰的认识,不过在上面我们也提到了自注意力机制的缺陷就是:模型在对当前位置的信息进行编码时,会过度的将注意力集中于自身的位置,因此作者提出了通过多头注意力机制来解决这一问题。同时,使用多头注意力机制还能够给予注意力层的输出包含有不同子空间中的编码表示信息,从而增强模型的表达能力。
Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions.
在说完为什么需要多头注意力机制以及使用多头注意力机制的好处之后,下面我们就来看一看到底什么是多头注意力机制。
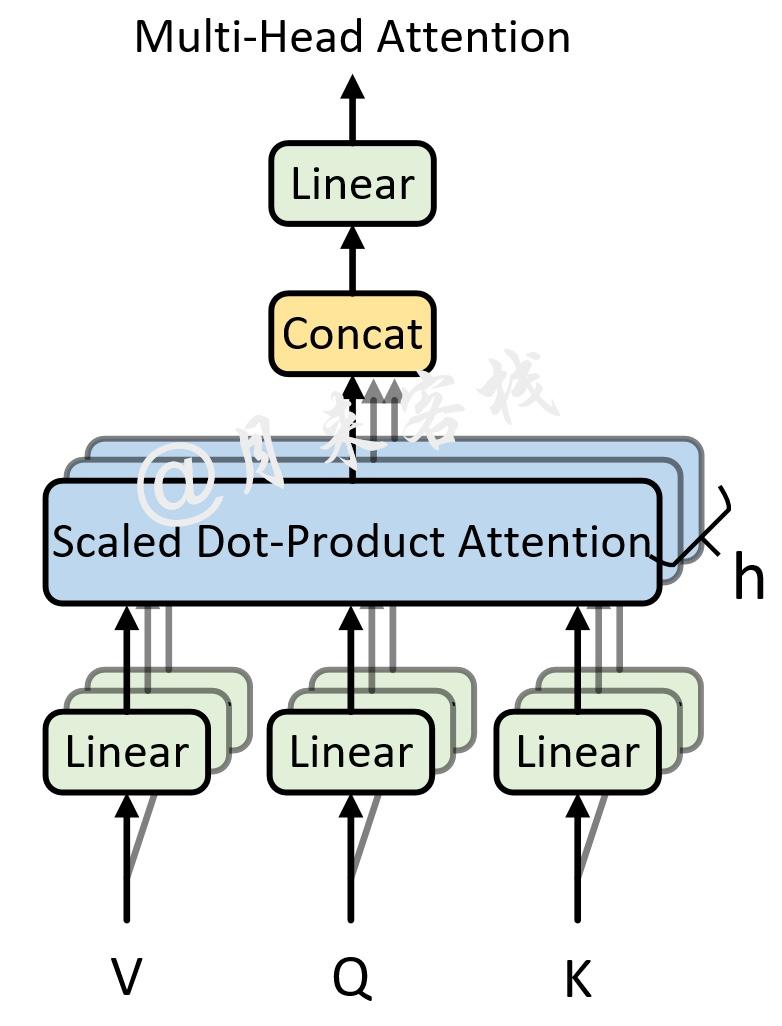
如上图所示,可以看到所谓的多头注意力机制其实就是将原始的输入序列进行多组的自注意力处理过程;然后再将每一组自注意力的结果拼接起来进行一次线性变换得到最终的输出结果。
具体的,其计算公式为:
\operatorname{MultiHead}(Q, K, V) = Concat \left(\right. head _{1}, \ldots , head \left._{h}\right) W^{O} \\
where \operatorname{head}_{i} = \operatorname{Attention}\left(Q W_{i}^{Q}, K W_{i}^{K}, V W_{i}^{V}\right)
\end{array}
其中
同时,在论文中,作者使用了个并行的自注意力模块(8个头)来构建一个注意力层,并且对于每个自注意力模块都限定了d_{k}=d_{v}=d_{model}/h=64。从这里其实可以发现,论文中所使用的多头注意力机制其实就是将一个大的高维单头拆分成了h个多头。因此,整个多头注意力机制的计算过程我们可以通过下图所示的过程来进行表示。
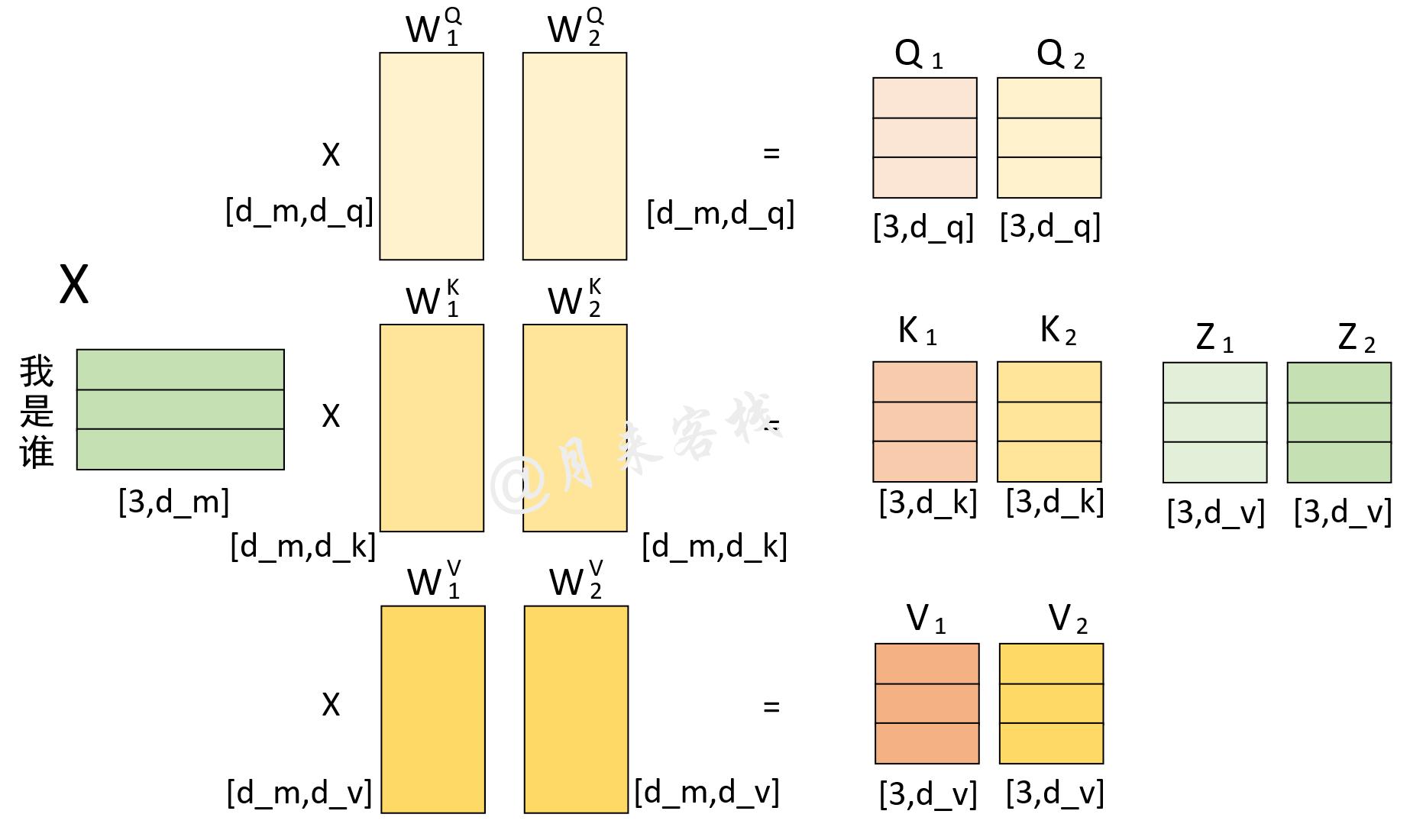
根据上图所示,根据输入序列X和W_{1}^{Q},W_{1}^{K},W_{1}^{V},我们计算得到了Q_{1},K_{1},V_{1},进一步根据公式得到了单个自注意力模块的输出Z_{1};同理,根据输入序列X和W_{2}^{Q},W_{2}^{K},W_{2}^{V}就得到了另外一个自注意力模块输出Z_{2}。最后将Z_{1},Z_{2}水平堆叠成Z,然后再用Z乘以W^{0}便得到了整个多头注意力层的输出。同时根据上上个图,还可以得到d_{q}=d_{k}=d_{v}。
到此,对于整个Transformer的核心部分,即多头注意力机制的原理就介绍完了。
4 总结
在本篇文章中,笔者首先介绍了论文的动机,包括传统网络结构所面临的问题以及作者所提出的应对办法;然后介绍了什么是自注意力机制以及其对应的原理;最后介绍了什么是多头注意力机制以及使用多头注意力的好处。同时,对于这部分内容来说,重点需要理解的就是自注意力机制计算原理与过程。在下一篇文章中,笔者将会详细介绍Transformer的位置编码与编码解码过程。
本文作者:StubbornHuang
版权声明:本文为站长原创文章,如果转载请注明原文链接!
原文标题:Transformer – 理解Transformer必看系列之,1 Self-Attention自注意力机制与多头注意力原理
原文链接:https://www.stubbornhuang.com/2280/
发布于:2022年08月01日 8:53:03
修改于:2024年03月08日 13:45:22
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。
评论
57