




深度学习 – 图解Transformer,小白也能看懂的Transformer处理过程
译自:https://jinglescode.github.io/2020/05/27/illustrated-guide-transformer/
1 前言
Transformer是encoder-decoder架构的进一步演变,其在论文Attention is All You Need中提出。虽然encoder-decoder架构一直依赖循环神经网络RNN提取序列信息,但是Transformer不使用RNN。基于Transformer的模型已经开始逐渐取代基于LSTM的模型,并且在许多序列到序列的问题上被证明具有很强的优越性。
Transformer完全依赖于注意力机制并且可以通过并行化提高速度。它在机器翻译领域取得最佳的进展。除了语言翻译领域的巨大进展之外,Transformer还提供了一种新的架构用于处理其他类型的任务,比如说文本摘要、视频字幕、语音识别等。
2 RNN
在Transformer之前,循环神经网络RNN一直是序列到序列数据建模的首选。RNN就像一个前馈神经网络一样处理序列数据,将输入一个接一个的展开到序列上。

展开输入的每个符号的过程由编码器完成,其目标是输入序列中提取特征数据并将其编码为向量,作为输入的表现形式。
一个典型的输入序列数据就是句子,RNN按句子中词的顺序提取每一个单词的特征,并组成为一个句子的特征表示。该表示将作为分类器的输入特征,用于输出固定长度的向量。
在机器翻译或者视频字幕应用领域,我们可以使用解码器代替输出固定长度的分类器。与编码器一样,解码器在多个时间步长上生成输出符号。

例如,在机器翻译的过程中,如果输入的是英文句子,输出是法语句子。Encoder编码器按顺序编码英文句子中的每一个单词,然后生成固定长度的向量表示。然后Decoder解码器将Encoder的固定长度的向量作为输入,依次生成每个法语单词,最后形成翻译之后的法语句子。
3 基于Encoder-Decoder的RNN的问题
RNN的一个明显的问题是模型训练的很慢,并且无法处理长序列数据。
在RNN中,输入数据需要一个一个地依次处理,这种处理方式使其无法使用GPU进行并行处理。RNN 非常慢,尽管其引入了截断反向传播来限制反向传播中的时间步数用于计算梯度和更新权重,但是RNN 的训练速度仍然很慢。
其次,RNN不能很好地处理长序列数据,如果输入的序列数据过长,会出现梯度消失和爆炸(一般在训练过程中会看到loss为NaN),这就是常说的RNN的长期依赖的问题。

1997年,Hochreiter & Schmidhuber提出了Long Short-Term Memory(LSTM)网络,该网络为了解决RNN的长期依赖性问题而设计。每个LSTM单元允许过去的信息跳过当前的单元的所有处理并移动到下一个单元,这允许内存保留更长时间,并使得数据能够随着它一直流动而不变。LSTM由输入门和遗忘门组成,输入门决定存储哪些新信息,遗忘门决定删除哪些信息。

LSTM网络除了改进记忆,并且能过处理比RNN更长的序列,但是由于LSTM更加复杂,使得LSTM与RNN相比更慢。
基于Encoder-Decoder的RNN架构的另一个缺点是固定长度向量。使用固定长度向量表示一个输入序列,并且将其用于解码一个全新的句子是很困难的。如果输入序列很大,则上下文向量无法存储所有信息,此外,区分具有相似词但是具有不同含义的句子具有挑战性。

如果使用一个固定长度的向量表示上述图片中的输入文字,然后在不参考上下文的基础上翻译整段文字这是很困难的。正确的做法是,当我们将句子从一种语言翻译成另一种语言时,我们会逐部分查看句子,每次都关注句子的特定短语。
Bahdanau提出了一种在Encoder-Decoder的模型中搜索与预测目标词相关的源语句部分的方法,而这就是Attention机制。我们可以使用Attention机制在不影响其性能的基础上翻译相对较长的句子。例如,翻译"noir"(法语中意为黑色),Attention机制将关注“black”这个词,可能还有"cat",而忽略句子中的其他词。

Attention机制提高了Encoder-Decoder的性能,但是因为RNN仍然需要按顺序逐字处理输入数据,导致速度依然是很大的性能瓶颈。
4 到底怎样才能并行化处理序列化数据?
Transformer于2017年提出,就想上文中提到的Encoder-Decoder架构一样,在Transformer中,输入序列被输入到编码器中,然后解码器一个一个地预测每个单词。但是,Transformer通过消除RNN和注意力机制提高其时间复杂度和性能。

还是以句子从英语翻译成法语为例子。在RNN中,每个隐藏状态都依赖于之前单词的隐藏状态。因此,当前步骤的嵌入是一次生成一个时间步骤。使用Transformer,没有时间步长的概念;输入序列可以并行传入编码器。
5 Transformer
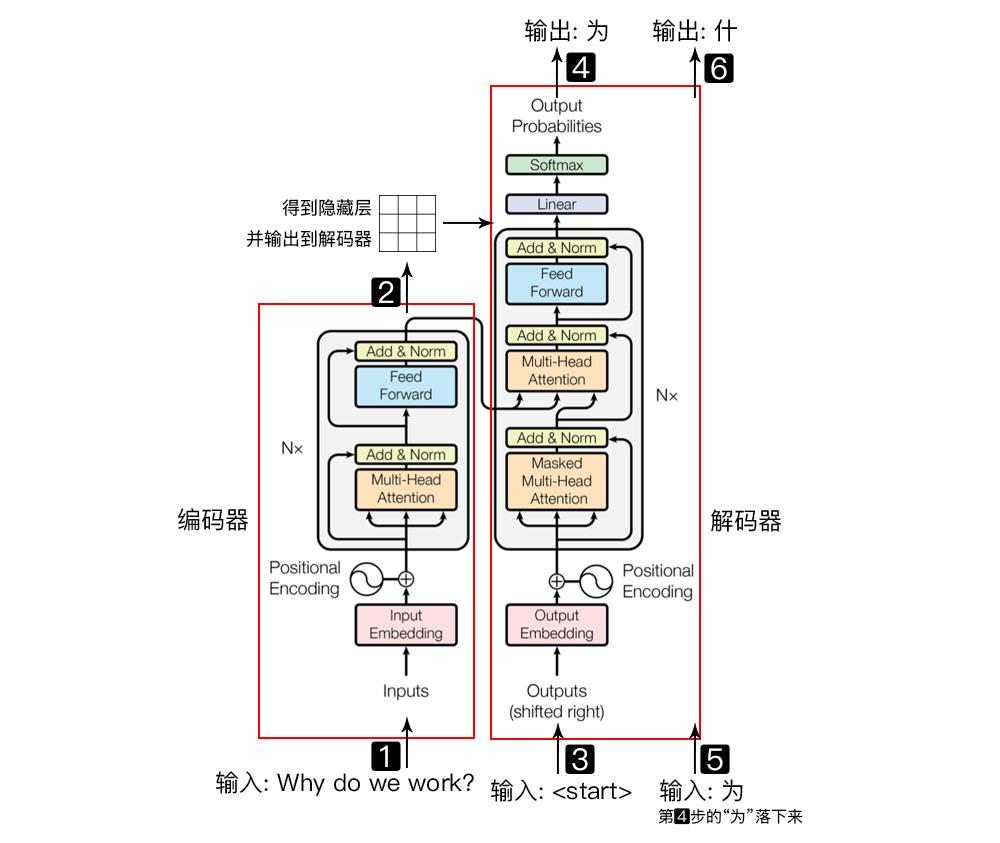
假设我们正在训练一个将英语句子翻译成法语的模型。Transformer架构有两部分,编码器(左)和解码器(右)。Transformer架构如下图所示。

如果输入一个英文句子到编码器中,编码器将输出每个单词的一组编码向量。输入的英文句子的每个单词都被转换成一个embedding用于表示含义。然后通过添加一个位置向量来添加句子中单词的上下文。这些词向量被输入到编码器的注意力块中,这些注意力块计算每一个词的注意力向量。这些注意力向量通过前馈神经网络并行传入到编码器中,然后编码器将输出每一个单词的一组编码向量。
解码器接收法语单词的输入和整个英语句子的注意力向量,以生成下一个法语单词。它使用embedding layer对每个单词的含义进行编码。然后添加位置向量来表示句子中单词的上下文。这些词向量被送入第一个注意块,即masked attention block。masked attention block计算当前词和先前单词的注意力向量。来自编码器和解码器的注意力向量被输入下一个注意力块,它为每个英语和法语单词生成注意力映射向量。这些向量被传递到前馈层线性层和softmax层来预测下一个法语单词。我们重复此过程以生成下一个单词,直到生成“句子结尾”标记。
上述过程是Transformer数据处理的细节,之后让我们更加深入的研究每一个组件。
5.1 Embeddings
因为计算机不理解单词,我们需要使用向量代替表示单词。词向量或者embeddings允许将每个词映射到高维嵌入空间中,其中具有相似含义的词彼此更接近。
尽管我们可以用向量来引用和表示每个单词的含义,因为不同句子中的同一个词可能具有不同的含义,所以单词的真正含义取决于句子中的上下文。由于RNN被设计用于捕获序列信息,那么在没有RNN的情下,Transformer如何该处理词序?我们需要positional encoders(位置编码器)。
5.2 Positional encoders
位置编码器从输入的embeddings layer接收信息并应用相对位置信息。该层输出带有位置信息的词向量,就是这个词的意思以及他再句子中的上下文。
我们看以下句子,“The dog bit Johnny”和“Johnny bit the dog”。如果没有上下文信息,两个句子将有相同的词向量(embeddings),但是这肯定是不正确的。

作者建议使用多个正弦和余弦函数来生成位置向量。我们可以将这个位置编码器用于任何长度的句子。波的频率和偏移对于每个维度都不同,代表每个位置,值在-1和1之间。

这种二进制编码方法还允许我们确定两个单词是否彼此靠近。例如,通过参考低频正弦波,如果一个词是“高”而另一个是“低”,我们知道它们之间的距离更远,一个在开头,另一个在结尾。
5.3 Encoder’s Multi-Head Attention
Attention机制主要是回答"what part of the input should I focus on?"这个问题。如果我们正在编码一个英语句子,我们想要回答的问题是“how relevant is a word in the English sentence relevant to other words in the same sentence?”。对于每一个单词,我们可以生成一个注意力向量来捕获句子中单词之间的上下文关系。例如,对于“black”这个词,注意力机制专注于“black”和“cat”。

由于我们对不同单词之间的交互感兴趣,每个单词的注意力向量可能对自己的权重过高。因此,我们需要一种方法来规范化向量。Attention块接受输入 V、K 和 Q,这些是提取输入词的不同分量的抽象向量。我们使用这些来计算每个单词的注意力向量。
为什么叫“Multi-Head Attention”?那是因为我们对每个单词使用了多个Attention向量,并采用加权平均来计算每个单词的最终Attention向量。
5.4 Encoder’s feed-forward
由于Multi-Head Attention块输出多个Attention向量,我们需要将这些向量转换为每个单词的单个 Attention向量。
这个前馈层从多头注意力接收注意力向量。我们应用归一化将其转换为单个注意力向量。因此,我们得到一个向量,这个向量可以被下一个编码器块或解码器块消化。在论文中,作者在输出到解码器块之前堆叠了六个编码器块。
5.5 Decoder’s output embedding and positional encoders
由于我们正在从英语翻译成法语,因此我们将法语单词输入到解码器。我们将词转化为词向量(embedding),然后我们添加位置向量以获得句子中词的上下文概念。我们可以将这些包含单词含义及其在句子中的上下文的向量输入到解码器块中。
5.6 Decoder’s Masked Multi-Head Attention
类似于编码器块中的多头注意力。Attention 块为法语句子中的每个单词生成Attention向量,以表示每个单词与同一输出句子中的每个单词的相关程度。
与编码器中的Attention块接收英文句子中的每个单词不同,只有法语句子的前面单词被输入到这个 解码器的Attention块中。因此,我们使用向量来掩盖稍后出现的单词并将其表示为零,因此注意力网络在执行矩阵运算时无法使用它们。

5.7 Decoder’s Multi-Head Attention
这个Attention块充当Encoder-Decoder,它接收来自编码器的multi-head Attention和解码器的 Masked Multi-Head Attention的向量。这个注意块将确定每个词向量彼此之间的相关程度,这就是从英语到法语单词的映射发生的地方。该块的输出是英语和法语句子中每个单词的注意力向量,其中每个向量表示与两种语言中其他单词的关系。

5.8 Decoder’s feed-forward
与编码器的前馈层一样,该层将由多个向量组成的每个单词归一化为单个Attention向量,用于下一个解码器块或线性层。在论文中,作者在输出到线性层之前堆叠了六个解码器块。
5.9 Decoder’s linear layer and softmax
由于解码器的目的是预测后面的单词,所以这个前馈层的输出大小是词汇表中法语单词的数量。Softmax将输出转化为概率分布,输出一个词对应于下一个词的最高概率。

对于每个生成的单词,我们重复这个过程,包括法语单词,并用它来生成下一个直到句子结束的标记生成。
6 Pytorch中使用Transformer
Github:https://gist.github.com/jinglescode/a1751ee6c2bec1c61ca4833ce8c9b98e#file-transformer-pytorch-py
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn import TransformerEncoder, TransformerEncoderLayer
class TransformerModel(nn.Module):
def __init__(self, ntoken, ninp, nhead, nhid, nlayers, dropout=0.5):
super(TransformerModel, self).__init__()
self.src_mask = None
self.pos_encoder = PositionalEncoding(ninp, dropout)
encoder_layers = TransformerEncoderLayer(ninp, nhead, nhid, dropout)
self.transformer_encoder = TransformerEncoder(encoder_layers, nlayers)
self.encoder = nn.Embedding(ntoken, ninp)
self.ninp = ninp
self.decoder = nn.Linear(ninp, ntoken)
self.init_weights()
def _generate_square_subsequent_mask(self, sz):
mask = (torch.triu(torch.ones(sz, sz)) == 1).transpose(0, 1)
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask
def init_weights(self):
initrange = 0.1
self.encoder.weight.data.uniform_(-initrange, initrange)
self.decoder.bias.data.zero_()
self.decoder.weight.data.uniform_(-initrange, initrange)
def forward(self, src):
if self.src_mask is None or self.src_mask.size(0) != len(src):
device = src.device
mask = self._generate_square_subsequent_mask(len(src)).to(device)
self.src_mask = mask
src = self.encoder(src) * math.sqrt(self.ninp)
src = self.pos_encoder(src)
output = self.transformer_encoder(src, self.src_mask)
output = self.decoder(output)
return output
class PositionalEncoding(nn.Module):
"Implement the PE function."
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) *
-(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + Variable(self.pe[:, :x.size(1)],
requires_grad=False)
return self.dropout(x)
参考文献
本文作者:StubbornHuang
版权声明:本文为站长原创文章,如果转载请注明原文链接!
原文标题:深度学习 – 图解Transformer,小白也能看懂的Transformer处理过程
原文链接:https://www.stubbornhuang.com/2186/
发布于:2022年06月29日 16:25:56
修改于:2024年03月08日 13:46:41
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。
评论
57