






深度学习 – CTC解码算法详解
原文链接:https://xiaodu.io/ctc-explained/
原文作者:yudonglee
本文总共分为五部分来全面阐述CTC算法(本篇为Part 1):
Part 1:Training the Network(训练算法篇),介绍CTC理论原理,包括问题定义、公式推导、算法过程等。Part1 链接
Part 2:Decoding the Network(解码算法篇),介绍CTC Decoding的几种常用算法。Part2 链接
Part 3:CTC Demo by Speech Recognition(CTC语音识别实战篇),基于TensorFlow实现的语音识别代码,包含详细的代码实战讲解。
Part 4:CTC Demo by Handwriting Recognition(CTC手写字识别实战篇),基于TensorFlow实现的手写字识别代码,包含详细的代码实战讲解。
Part 5:Conclusion(总结展望篇),总结CTC算法的理论局限性和适用场景,以及近年来相关的最新研究动态。
在上一篇文章中我们详细介绍了CTC问题背景和模型训练的算法和原理,本篇是整体的第二部分,重点介绍CTC模型预测-解码算法。
1 为什么需要CTC解码算法?
一般在分类问题中,训练好模型之后,模型的预测过程非常简单,只需要加载模型文件从前到后执行即可得到分类结果。但在序列学习问题中,模型的预测过程本质是一个空间搜索过程,也称为解码,如何在限定的时间条件下搜索到最优解是一个非常有挑战的问题。下面,我们来详细介绍CTC的解码算法。
对CTC网络进行Decoding解码本质过程是选取条件概率最大的输出序列,即满足:argmax_{y} P(y|x)。

在上图中,解码单元为{a,b,_} , 输入序列长度为2,横轴为时间序列,纵轴为解码单元,栅格中的数字为输出概率。
如上图的例子,按照时间序列展开得到栅格网络,解码的过程相当于空间搜索。我们可以选择暴力的解码策略:穷举搜索,但时间复杂度是指数级的N^{T},显然不可行。我们也可以选择简单的解码策略:在每一步选择概率最大的输出值,这样就可以得到最终解码的输出序列(如上图例子,最终解码的输出序列l=blank)。然而,根据上一篇介绍我们知道,CTC网络的输出序列只对应了搜索空间的一条路径,一个最终标签可对应搜索空间的N条路径,所以概率最大的路径并不等于最终标签的概率最大,即不是最优解(如上图例子,最优解是p(l=b)而不是p(l=blank))。
本篇我们介绍两种常见的CTC解码算法:CTC Prefix Search Decoding和CTC Beam Search Decoding。简而言之,Prefix Search Decoding是基于前缀概率的搜索算法,它能确保找到最优解,但最坏情况下耗时可能会随着序列长度呈指数增长;CTC Beam Search Decoding是一种Beam Search算法,它能在限定时间下找到近似解,但不保证一定能找到最优解。
2 CTC解码算法
2.1 CTC Prefix Search Decoding
CTC Prefix Search Decoding本质是贪心算法,每一次搜索都会选取“前缀概率”最大的节点扩展,直到找到最大概率的目标label,它的核心是利用动态规划算法计算“前缀概率”。下面先通过一个简单的例子来介绍CTC Prefix Search Decoding的大致过程,如下图。
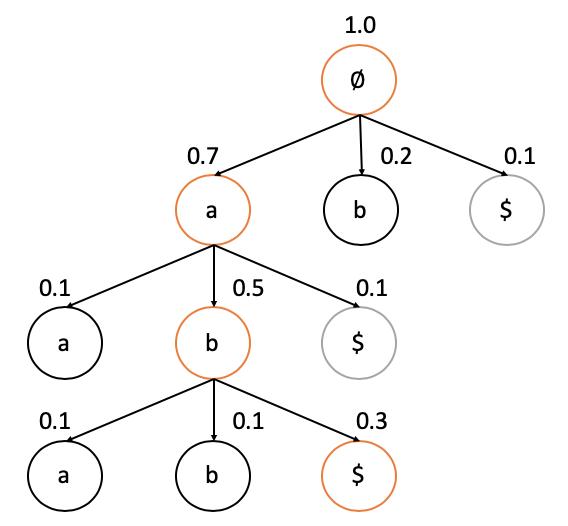
上图中,最终label对应的字符集为{a,b},从根节点开始搜索扩展,其子节点为a、b,ab为结束节点(表示不可往下扩展子节点),最终搜索过程会在结束节点上停止,并输出最终的解码label和概率值。
如上图例子,CTC Prefix Search搜索过程如下:
(1)初始化最佳序列l^{\ast }为空集,最佳序列概率为 P(l^{\ast } )。把根节点放入到扩展集合中,初始化它的前缀概率为1.0,初始化P(l^{\ast } = 0)。
(2)从扩展集合中选取前缀概率最大的节点扩展,扩展子节点a和b,计算a和b的前缀概率(上图中第一层节点a和b的前缀概率分别为0.7和0.2),如果前缀概率大于P(l^{\ast } )则将其加入到扩展集合。同时,计算结束节点的概率(上图中第一层节点\circledS 的概率为0.1),如果结束节点的概率大于P(l^{\ast } ),则将其对应的label设置为最佳序列l^{\ast },同时更新P(l^{\ast } )。
(3)继续搜索,重复步骤2,直到扩展集合为空,即搜索结束,输出最终解码的l^{\ast }和概率P(l^{\ast } ),上图中,最终l^{\ast }=ab,P(l^{\ast } )=0.3。
从上面的例子中可以看出,CTC Prefix Search的搜索过程非常简单,核心问题是如何计算前缀概率和每个结束节点对应的概率,它们的计算方式跟上一篇介绍前向概率和后向概率的动态规划算法类似,下面来正式介绍它们的定义与计算方式。
定义t时刻前缀为\rho的概率为\gamma (\rho ,t):即在t时刻网络输出序列对应的label为\rho的概率。将\gamma (\rho ,t)划分为两种情况,
(a)\gamma-(\rho ,t)定义为t时刻网络输出blank空字符的概率;
(b)\gamma+(\rho ,t)定义为t时刻网络输出非空字符的概率,则\gamma(\rho ,t) = \gamma-(\rho ,t) + \gamma+(\rho ,t)
更加正式的定义如下:
定义L为建模单元的字符集(如上图例子中的{a,b}),L^{\prime }为加入blank空字符后的扩展字符集(如上图中的{a,b,-}),\beta是网络输出路径\pi到输出序列l的映射函数:\beta (\pi ) = l,
路径集合
t时刻的前缀\prime的概率为:
\gamma (\rho ,t)=\sum P(\pi|x) (\pi \in Y) \\
\gamma+(\rho ,t)=\sum P(\pi|x) (\pi \in Y,\pi_{t}=\rho_{ \left | \rho \right | } ) \\
\gamma-(\rho ,t) = \sum P(\pi|x) (\pi \in Y,\pi_{t} = blank ) \\
\end{array}
最终序列l(假定输入序列长度为T)的概率为:
p(\rho |x) = \gamma (\rho ,t) = \gamma- (\rho ,t)+\gamma+ (\rho ,t),p(\rho... |x)= {\textstyle \sum_{s\ne \phi }^{p}}(\rho + s|x)
\end{array}

上图为CTC Prefix Search的算法过程。
在给定足够时间的条件下CTC Prefix Search Decoding总能搜索到最大概率值,但随着输入序列长度的增加,搜索过程扩展的前缀可能呈指数级增加。所以在实际应用中为了能够在限定时间的条件下找到近似解,需要增加一些启发式的搜索剪枝策略,比如,分而解之的思路:将搜索空间按照空字符blank来划分为更小的子空间,再针对每个子空间进行CTC Prefix Search。
另外,在语音识别等实际应用中,解码过程往往还要加上一些条件约束,即满足
argmax_{l} p(l|x,G)
\end{array}
其中G可以是语音模型或者语法等约束,取决于具体应用条件设定。
p(l|x,G) = \frac{p(l|x)p(l|G)p(x)}{p(x|G)p(l)}
\end{array}
假定p(x)p(x|G)p(l)的概率同等,则解码的目标是:
argmax_{y} p(l|x)p(l|G)
\end{array}
所以,实际应用中可以在解码过程加上限定约束条件,比如,在语音识别中p(l|G)可以对应为语言模型或发音模型的概率。
2.2 CTC Beam Search Decoding
CTC Beam Search Decoding算法虽然简单,但在实际中应用广泛,我们有必要深入了解它的具体实现细节。Beam Search的过程非常简单,每一步搜索选取概率最大的W个节点进行扩展,W也称为Beam Width,其核心还是计算每一步扩展节点的概率。我们先从一个简单的例子来看下搜索的穷举过程,T=3,字符集为{a, b},其时间栅格表如下图:
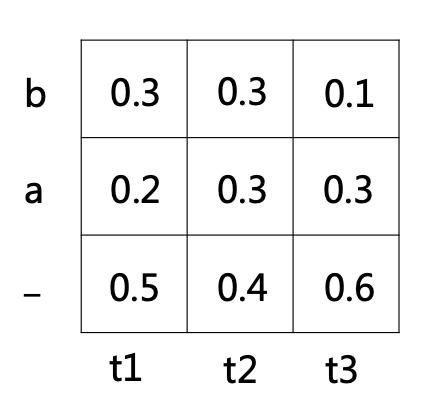
上图中,横轴表示时间,纵轴表示每一步输出层的概率,T=3,字符集为{a, b}。
如果对它的搜索空间进行穷举搜索,则每一步都展开进行搜索,如下图所示:
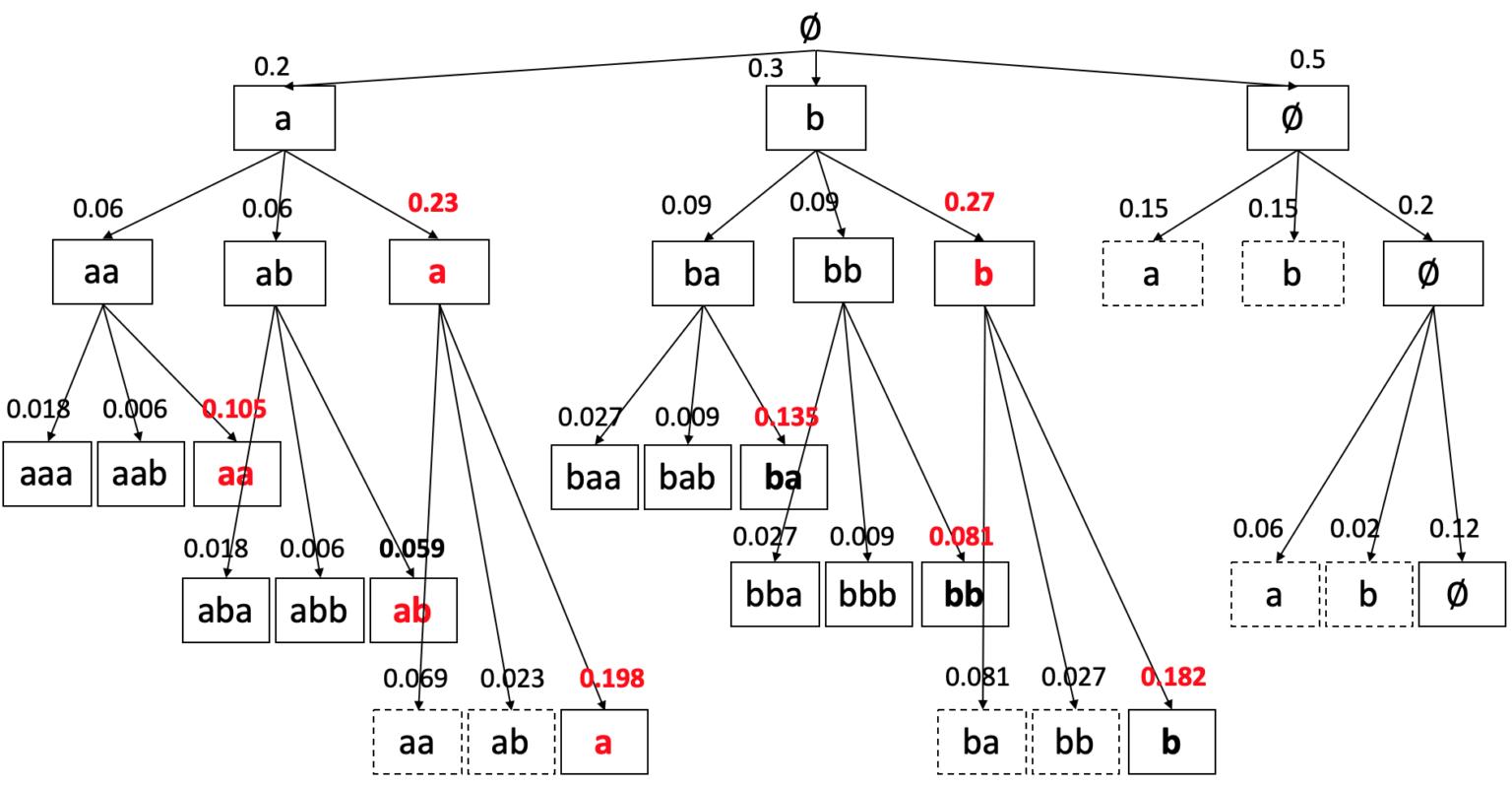
如上所述,穷举搜索每一步都要扩展全部节点,能保证最终找到最优解(上图中例子最优解l^{\ast }=b,p(l^{\ast })=0.164),但搜索复杂度太高,而Beam Search的思路很简单,每一步只选取扩展概率最大的W个节点进行扩展,如下图所示:
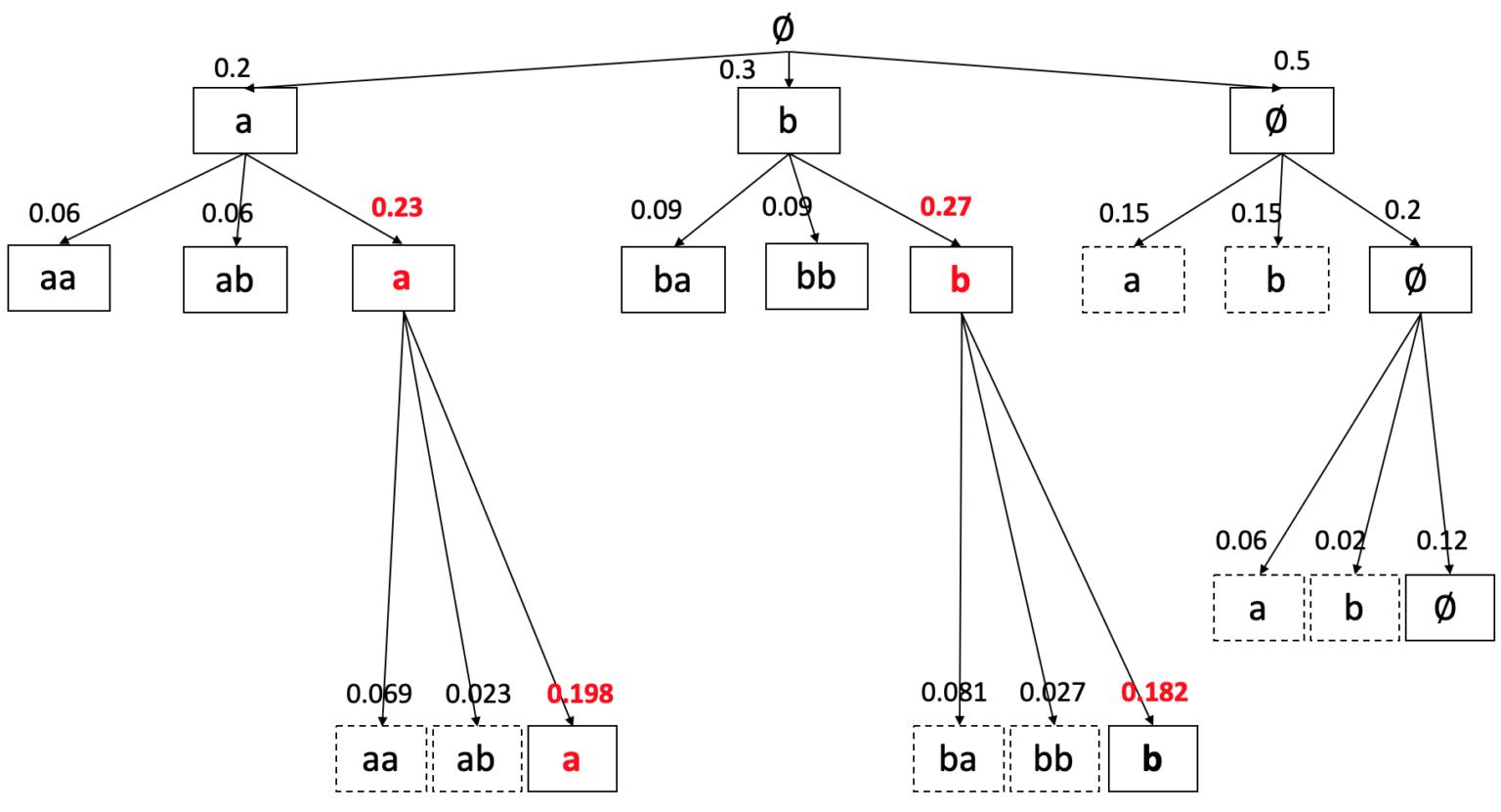
由此可见,Beam Search实际上是对搜索数进行了剪枝,使得每一步最多扩展W个节点,而不是随着T的增加而呈指数增长,降低了搜索复杂度。
下面我们再介绍CTC Beam Search中最核心的一步,计算节点扩展概率:\gamma (\rho ,t)。跟上一节一样,定义t时刻前缀为\rho的概率为\gamma (\rho ,t):即在t时刻网络输出序列对应的label为\rho的概率。
另外,
(1)定义\hat{\rho}为\rho的前继前缀,比如\rho=ab,则\hat{\rho}=a;
(2)定义\rho ^{e}为字符串\rho的结尾字符,比如\rho=abc,则\rho ^{e}=c;
(3)定义\hat{\rho } ^{e}为字符串\hat{\rho}的结尾字符,比如\hat{\rho}=ab,则\hat{\rho } ^{e} = b;
将\gamma (\rho ,t)划分为两种情况,
(a)\gamma-(\rho ,t)定义为t时刻网络输出blank空字符的概率;
(b)\gamma+(\rho ,t)定义为t时刻网络输出非空字符的概率,则\gamma(\rho ,t) = \gamma-(\rho ,t) + \gamma+(\rho ,t)
我们可以递归求解\gamma-(\rho ,t)和\gamma+(\rho ,t),如下
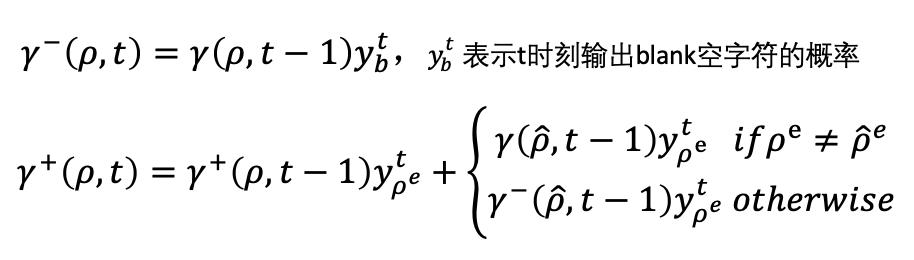
至此,CTC Beam Search的求解过程就基本介绍完了,如上一节所述,在实际应用中往往需要加上一些条件约束,比如语言模型或语法约束等,我们对扩展字符的过程加上约束,修改\gamma-(\rho ,t)和\gamma+(\rho ,t)的递归求解过程如下:
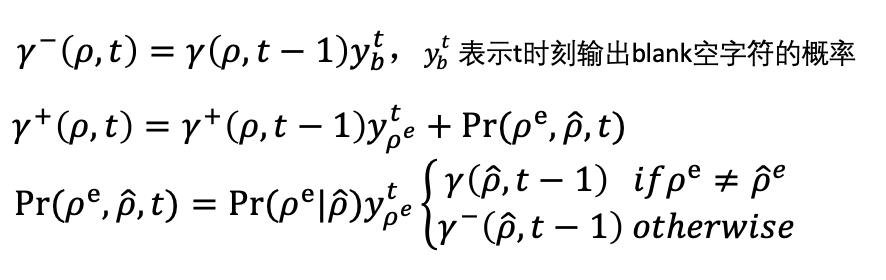
其中P_{r} (\rho ^{e} |\hat{\rho } )表示从\hat{\rho }到\rho的扩展概率。
综上所述,CTC Beam Search的算法过程如下:

参考文献
- Graves et al., Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with RNNs. In ICML, 2006. (Graves提出CTC算法的原始论文)
- Graves et al., A Novel Connectionist System for Unconstrained Handwriting Recognition. In IEEE Transactions on PAML, 2009.(CTC算法在手写字识别中的应用)
- Graves et al., Towards End-to-End Recognition with RNNs. In JMLR, 2014.(CTC算法在端到端声学模型中的应用)
- Alex Graves, Supervised Sequence Labelling with Recurrent Neural Networks. In Studies in Computational Intelligence, Springer, 2012.( Graves 的博士论文,关于sequence learning的研究,主要是CTC)
本文作者:StubbornHuang
版权声明:本文为站长原创文章,如果转载请注明原文链接!
原文标题:深度学习 – CTC解码算法详解
原文链接:https://www.stubbornhuang.com/2173/
发布于:2022年06月19日 10:41:29
修改于:2023年06月25日 21:06:44
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。
评论
57